Alert History¶
Context¶
In NextGen UI we are introducing the Global Health Component that shows real time entity Health but also intends to show entity Health over the last X days. This Global Health Component is available in the System Health Monitor as well as in Metalk8s, xCore and XDM admin UIs. It applies to entities like Node, Volume, Platform, Storage Backends, etc.
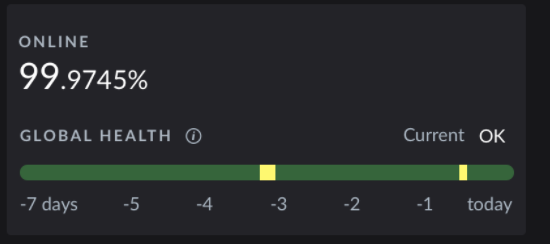
The entity Health is computed based on active alerts. In order to know the health of an entity as it was in the past, we would need to collect alerts that were active for this specific past time. As soon as the Platform or Storage Admin identifies a time at which the entity was degraded, he can access the detailed list of sub alerts impacting this entity.
Currently, once an active alert is cleared, it disappears from the System.
Goal¶
In order to achieve the UI functionality as described above, we would need to keep information about the alerts that were fired in the past:
The alert (all info that were available at the time the alert was fired)
When it was fired
When it was cleared
User Stories¶
As a Platform/Storage Admin, I want to know the health of a given NextGen entity over the past X days in order to ease root cause analysis.
Basically this should be achieved by collecting past alerts, belonging to this entity.
As a Platform/Storage Admin, I want to collect the list of sub alerts which contributed to the degradation on a specific entity in the past, in order to understand more in details the cause of the degradation.
Here we would need to access all sub alerts (contributing to the entity high level alert). This is related to the Alert grouping feature.
The X days to keep accessible is configurable and ideally matches with the history of other observability data (metrics and logs) in order to ease the correlation between various observability indicators. This configuration must be persistent across platform upgrades.
In conclusion, the system should retain all emitted alerts for a given configurable period.
The service exposing past alerts is to be used by NextGen Admin UIs. It can also be used by some NextGen tooling when it comes to create a support ticket. It will not be used by xCore or XDM data workloads and it will not be exposed for external usage.
Monitoring and Alerting¶
The service exposing past alerts should be monitored i.e. should expose key health/performance indicators that one can consume through dedicated Grafana dashboard. An alert should be triggered when the service is degraded.
Deployment¶
The said service is part of the infra service category and it is either deployed automatically or some documentation explains how to deploy it and provision storage for it.
It should support one node failure when deploying NextGen on more than 3 nodes, like for monitoring, alerting and logging services.
Future/Bonus Features¶
Dedicated Grafana Dashboard to navigate through the past alerts without focusing on a specific entity only. From this dashboard, one can select one or multiple labels as well as a specific period, in order to collect all alerts with a given set of labels.
A dump of the past alerts could be added to the sos report that one would generate when collecting all information to send to Scality support.
Design Choices¶
![@startuml(id=Container)
title Alert history - Containers
caption A detailed view of the alert history system.
skinparam {
shadowing false
arrowFontSize 10
defaultTextAlignment center
wrapWidth 200
maxMessageSize 100
}
hide stereotype
skinparam rectangle<<1>> {
BackgroundColor #08427b
FontColor #ffffff
BorderColor #dddddd
}
skinparam rectangle<<2>> {
BackgroundColor #1168bd
FontColor #ffffff
BorderColor #dddddd
roundCorner 20
}
skinparam rectangle<<6>> {
BackgroundColor #438dd5
FontColor #ffffff
BorderColor #dddddd
roundCorner 20
}
skinparam rectangle<<7>> {
BackgroundColor #438dd5
FontColor #ffffff
BorderColor #dddddd
roundCorner 20
}
skinparam rectangle<<8>> {
BackgroundColor #438dd5
FontColor #ffffff
BorderColor #dddddd
roundCorner 20
}
skinparam rectangle<<9>> {
BackgroundColor #438dd5
FontColor #ffffff
BorderColor #dddddd
roundCorner 20
}
rectangle "==MetalK8s Logging\n<size:10>[Software System]</size>" <<2>> as 2
rectangle "==User\n<size:10>[Person]</size>\n\nA MetalK8s user." <<1>> as 1
package "MetalK8s Monitoring\n[Software System]" {
rectangle "==Alert Logger\n<size:10>[Container]</size>\n\nService logging alerts received from Alertmanager." <<6>> as 6
rectangle "==Alertmanager\n<size:10>[Container]</size>\n\nService deduplicating, grouping and forwarding alerts." <<7>> as 7
rectangle "==Grafana\n<size:10>[Container]</size>\n\nService displaying metrics and logs through dashboards." <<9>> as 9
rectangle "==Prometheus\n<size:10>[Container]</size>\n\nService monitoring the cluster components." <<8>> as 8
}
7 .[#707070,thickness=2].> 6 : "Forwards alerts to"
9 .[#707070,thickness=2].> 2 : "Queries logs (alerts) from"
9 .[#707070,thickness=2].> 8 : "Queries metrics from"
2 .[#707070,thickness=2].> 6 : "Reads logs from"
8 .[#707070,thickness=2].> 7 : "Sends alerts to"
1 .[#707070,thickness=2].> 9 : "Consults alerts dashboard"
@enduml](../../_images/plantuml-a30da8a6b6e0cd30367a2fb101caa925365895b9.png)
Alertmanager webhook¶
To retrieve alerts sent by Alertmanager, we configure a specific receiver where it sends each and every incoming alerts. This receiver is a webhook which is basically an HTTP server listening on a port and waiting for HTTP POST request from Alertmanager. It then forwards alerts to the storage backend.
Alerts sent by Alertmanager are JSON formatted as follows:
{
"version": "4",
"groupKey": <string>, // key identifying the group of alerts (e.g. to deduplicate)
"truncatedAlerts": <int>, // how many alerts have been truncated due to "max_alerts"
"status": "<resolved|firing>",
"receiver": <string>,
"groupLabels": <object>,
"commonLabels": <object>,
"commonAnnotations": <object>,
"externalURL": <string>, // backlink to the Alertmanager.
"alerts": [
{
"status": "<resolved|firing>",
"labels": <object>,
"annotations": <object>,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>",
"generatorURL": <string> // identifies the entity that caused the alert
},
...
]
}
Alertmanager implements an exponential backoff retry mechanism, so We can not miss alerts if the webhook is unreachable/down. It will keep retrying until it manages to send the alerts.
Loki as storage backend¶
We use Loki as the storage backend for alert history because it provides several advantages.
First, it allows to easily store the alerts by simply logging them on the webhook container output, letting Fluent-bit forward the alerts to it.
Loki uses a NoSQL database, which is better to store JSON documents than an SQL one, allowing us to not have to create and maintain a database schema for the alerts.
Loki also provides an API allowing us to expose and query these alerts using the LogQL language.
Plus, since Loki is already part of the cluster, it saves us from having to install, manage and expose a new database.
Using Loki, we also directly benefit from its retention and purge mechanisms, making the alerts history retention time automatically aligned with all other logs (14 days by default).
Warning
There is a drawback in using Loki, if at some point its volume is full (because there is too much logs), we will not be able to store new alerts anymore, especially since there is no size-based purge mechanism.
Another issue is, since we share the retention configuration with the other logs, it is hard to ensure we will keep enough alert history.
As for now, there is no retention based on labels, streams, tenant or whatever (on-going discussion GH Loki #162).
Rejected Design Choices¶
Alertmanager API scraper¶
A program polling the Alertmanager API to retrieve alerts.
It generates more load and forces us to parse the result from the API to keep track of what we already forward to the storage backend or query it to retrieve the previously sent alerts.
Plus, it does not allow to have alerts in near to real time, except if we poll the API in a really aggressive manner.
If the scraper is down for a long period of time, we could also loose some alerts.
Dedicated database as storage backend¶
Using a dedicated database to store alerts history was rejected, because it means adding an extra component to the stack.
Furthermore, we would need to handle the database replication, lifecycle, etc.
We would also need to expose this database to the various components consuming the data, probably through an API, bringing another extra component to develop and maintain.
Implementation Details¶
Alertmanager webhook¶
We need a simple container, with a basic HTTP server running inside, simply handling POST requests and logging them on the standard output.
It will be deployed by Salt as part of the monitoring stack.
A deployment with only 1 replica will be used as we do not want duplicated entries and Alertmanager handles retry mechanism if the webhook is unreachable.
An example of what we need can be found here <https://github.com/tomtom-international/alertmanager-webhook-logger>.
Alertmanager configuration¶
The default Alertmanager’s configuration must be updated to send all alerts to this webhook.
Configuration example:
receivers:
- name: metalk8s-alert-logger
webhook_configs:
- send_resolved: true
url: http://<webhook-ip>:<webhook-port>
route:
receiver: metalk8s-alert-logger
routes:
- receiver: metalk8s-alert-logger
continue: True
This configuration must not be overwritable by any user customization
and the metalk8s-alert-logger receiver must be the first route to
ensure it will receive all the alerts.
Fluent-bit configuration¶
Logs from the webhook need to be handled differently than the other Kubernetes
containers.
Timestamps of the logs must be extracted from the JSON timestamp key and
only the JSON part of the log must be stored to make it easier to use by
automatic tools.
Expose Loki API¶
The Loki API must be reachable via the web UI, therefore it must be exposed through an ingress as it is already done for Prometheus or Alertmanager APIs.
Global Health Component Implementation¶
In order to build the Global Health Component the UI queries loki API to retrieve past alerts. The users have the ability to select a timespan for which they want to retrieve the alerts. The UI is using this timespan to query loki for alerts firing during this period. However Alertmanager is repeating webhooks for long running alerts to metalk8s-alert-logger at a defined pace in its configuration. This means that for example if an alert is firing since 6hours and alertmanager is configured to repeat the notification each 12 hours, querying loki for the last hour won’t list that alert. Additionnaly if alertmanager or loki or the platform itself goes down old alerts won’t be closed and new ones will be fired by alertmanager.
This leads to several issues that the UI have to solve when querying Loki to display the alert history: #. When the platform/alertmanager/loki goes down the UI has to compute the end time of an alert and set it to the end time period start timestamp. #. The alerts are duplicated in loki so the UI has to regroup them by fingerprint and start time.
We propose here to implement a useHistoryAlert hook in metalk8s ui which can be reused to retrieve past alerts. This useHistoryAlert takes a list of filters as a parameter. These filters allow consumers to search for alert history of alerts matching a specific set of labels or annotations. The signature of the hook is: useHistoryAlert(filters: {[label: string]: string}): Alert[].
This hook is used in conjonction with an AlertHistoryProvider which is responsible of alert fetching and transformation. It uses useMetricsTimeSpan hook to retrieve the period selected by the user and uses this period to fetch alerts on loki. It additionnaly retriveves platform/monitoring unavailbility periods by querying for alertmanager number of firing alerts metrics on Prometheus API. If the selected timespan is smaller than alertmanager notification period (period after which alertmanager recall Metalk8s alert logger to signify that the alert is still firing), the hook is then fetching the alerts for this period of time at minimum to ensure long firing alerts retrieval.
Once the downtime periods are retrieved they are converted to an UI alert object with a specific severity set to unavailable so that we can display an unavailable segment on the Global health bar.

Grafana dashboard¶
Alerts are already retrievable from the Logs dashboard, but it is not
user friendly as the webhook pod name must be known by the user and
metrics displayed are relative to the pod, not the alerts themselves.
A dedicated Grafana dashboard with the alerts and metrics related to them will be added.
This dashboard will be deployed by adding a ConfigMap
alert-history-dashboard in Namespace metalk8s-monitoring:
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-history-dashboard
namespace: metalk8s-monitoring
labels:
grafana_dashboard: "1"
data:
alert-history.json: <DASHBOARD DEFINITION>
Test Plan¶
Add a test in post-install to ensure we can at least retrieve the Watchdog
alert using Loki API.